This page contains information on how to use file transcription functionality for video/audio files with FAB Subtitler.
FAB Subtitler also supports live transcription of live video/audio streams which is described on a separate page
FAB Subtitler PRO/LIVE/MPEG supports the use of cloud based speech recognition services for transcription of audio from video/audio files to subtitle files with text and timecode. FAB Subtitler transfers audio from the video files to the cloud and the progress of the transfer and of the transcription can be viewed on the screen. When the cloud service finishes the transcription FAB Subtitler will download the JSON result file of the transcription and store it in a local folder and delete the video file in the cloud. It is also possible to configure FAB Subtitler to extract the audio from the video file and only transfer the audio to the cloud. Most transcription services only provide recognized text and timecode.
Some transcription services may provide additional information. Microsoft Video Indexer also provides the timecode of recognized scene changes and the speaker of the recognized text. FAB Subtitler will then display scene changes in the audio graph and the text for different speakers will be displayed in different colors (when this is configured in options of FAB Subtitler).
![]()
FAB Subtitler supports the following cloud transcription services:
The quality of the recognized text is generally not 100% perfect and it mostly requires some manual corrections in FAB Subtitler. However when using the transcription service the subtitle preparation process may require much less time because timecodes are generally already correct and only some text has to be corrected. For video material that works well with the selected transcription service up to 70% less time will be required to prepare the subtitles.
Configuration of FAB Subtitler
![]()
- “Store the result file of the transcription in a separate folder (not in the video folder)” instructs FAB Subtitler to store transcript result files in a separate folder and not in the folder with video files.
- “Maximum number of lines per subtitle” defines how many lines of text should be used in every subtitle for the recognized text when converting JSON result files returned by the transcription service to subtitle files.
- “Use spell check to automatically correct the transcript” defines that FAB Subtitler will use the spell check function to try to correct some errors returned by the transcription service
- “Assign colors to speakers when present in the transcript file” will instruct FAB Subtitler to use a different color for every speaker. This will however only work when the speaker ID is present in the transcript file returned by the transcription service.
Microsoft Video Indexer
To configure FAB Subtitler to use Microsoft Video Indexer as the transcription service open Options / Special / Transcription:
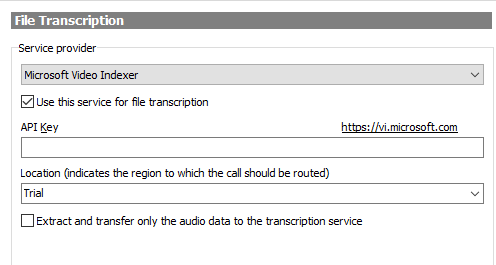
- API Key: The API Key is provided by Microsoft in the web interface of Microsoft Video Indexer so that external applications can use the Microsoft Video Indexer web service. Make sure to enter the API key for your Microsoft Video Indexer account. The following page describes how to obtain the API key:
- Location: The location of the service. For trial accounts you can use “Trial”
Google Speech to Text
To configure FAB Subtitler to use Google Cloud as the transcription service open Options / Special / Transcription:
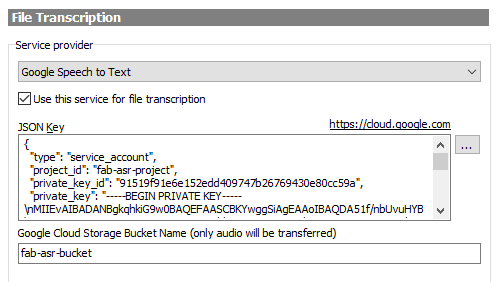
-
JSON Key: The JSON Key is a text file which has to be loaded from a JSON file or the content has to be copied into this field. You will find a description how to obtain the JSON key further below.
-
Google Cloud Storage Bucket Name: Enter the name of the storage bucket that will be used for storing of audio files transferred to the Google cloud. FAB Subtitler will always extract the audio from the video file and only transfer the audio to the Google cloud. The instructions below describe how to create a bucket. Please note that you will have to use a different bucket name (not fab-asr-bucket) because Google storage bucket names must be globally unique.
To configure the Google Cloud to be used with FAB Subtitler follow these instructions:
-
Visit https://cloud.google.com and create an account. In July 2018 Google offered a trial account with USD 300 credit which can be used within 12 months. This allows extensive testing of the Google cloud service.
-
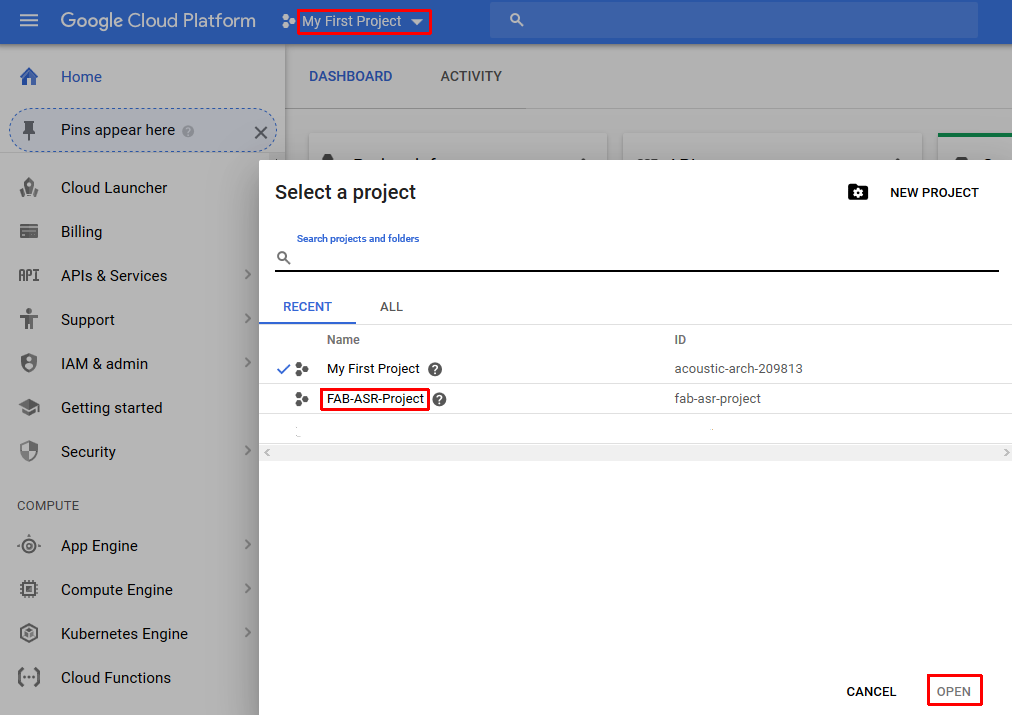
Before you can use the Google cloud you must first create a project. Create a project with the name FAB-ASR-Project as shown below
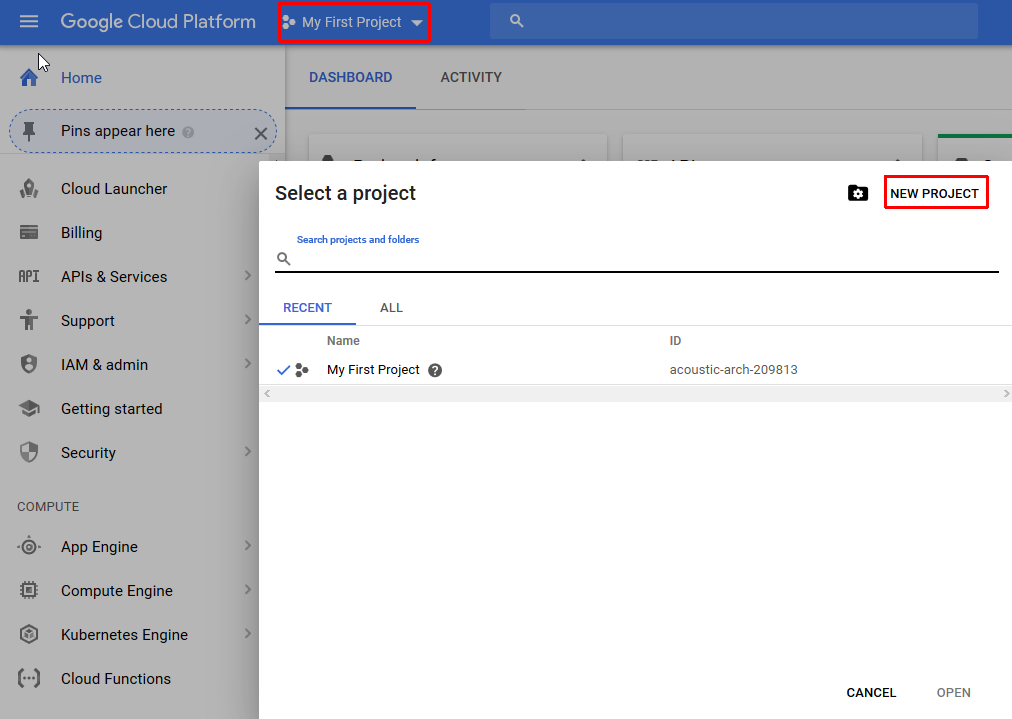
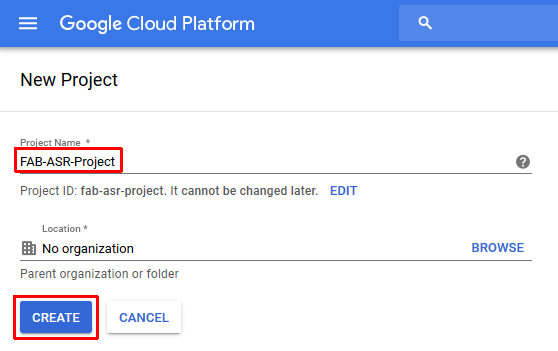
- Select the project FAB-ASR-Project as the current project
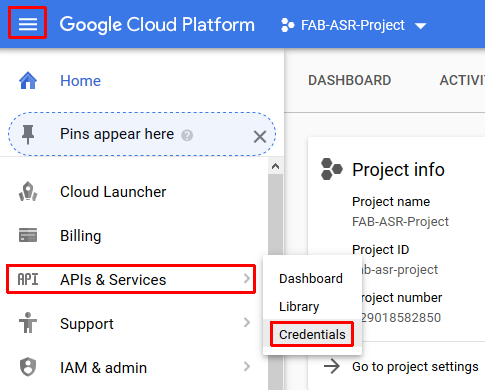
- Create Credentials for a new service account in the API Manager
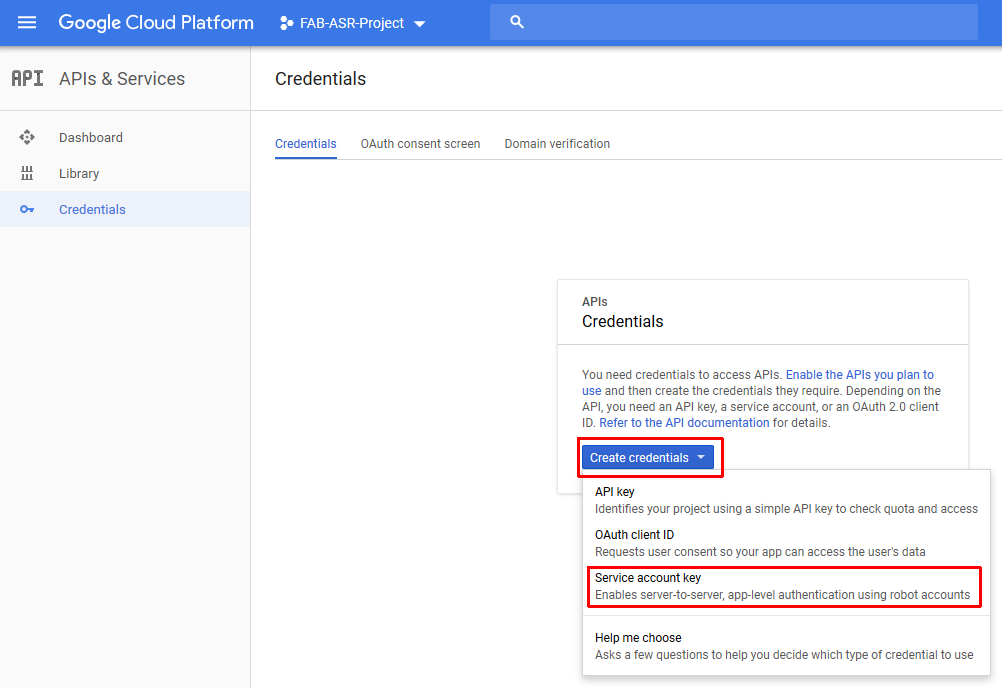
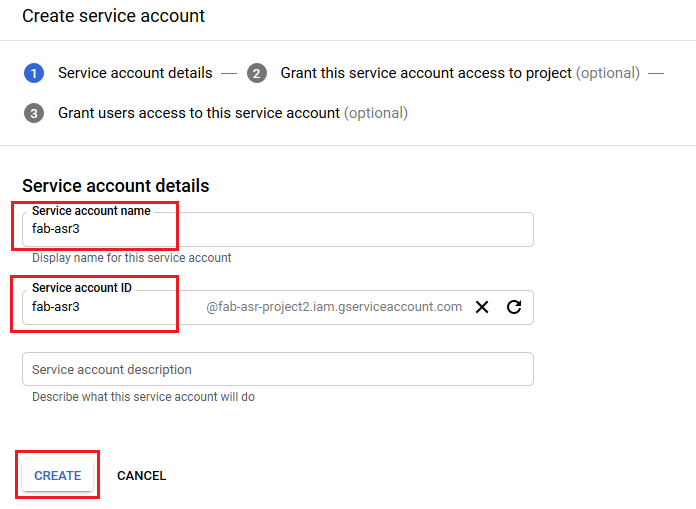
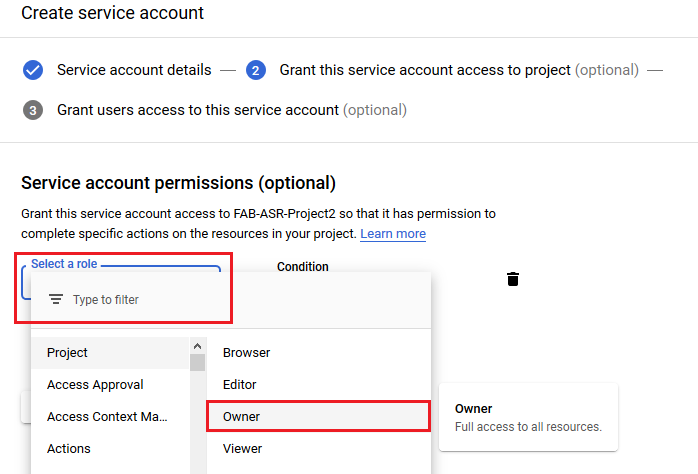
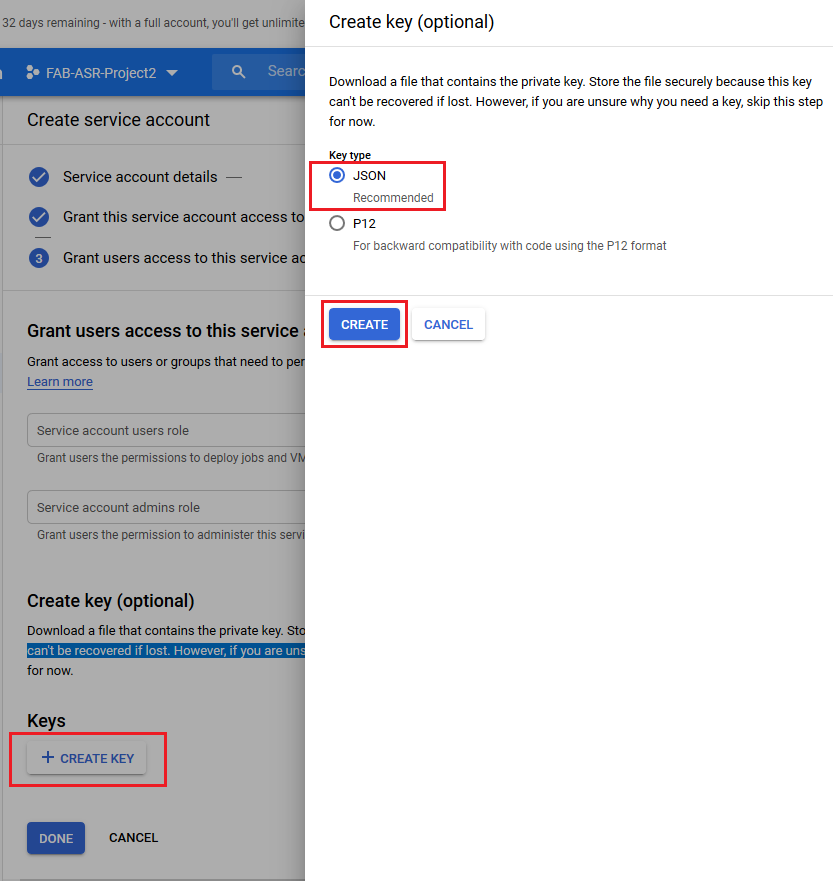
-
After the previous step the JSON file with the credentials for the new service account will be downloaded to the computer. The JSON file shall be imported into FAB Subtitler Options /Special / Transcription / Google Speech to Text.
-
Create the storage bucket with a globally unique name (do not use fab-asr-bucket). The bucket will be used to store audio files for transcription in the cloud
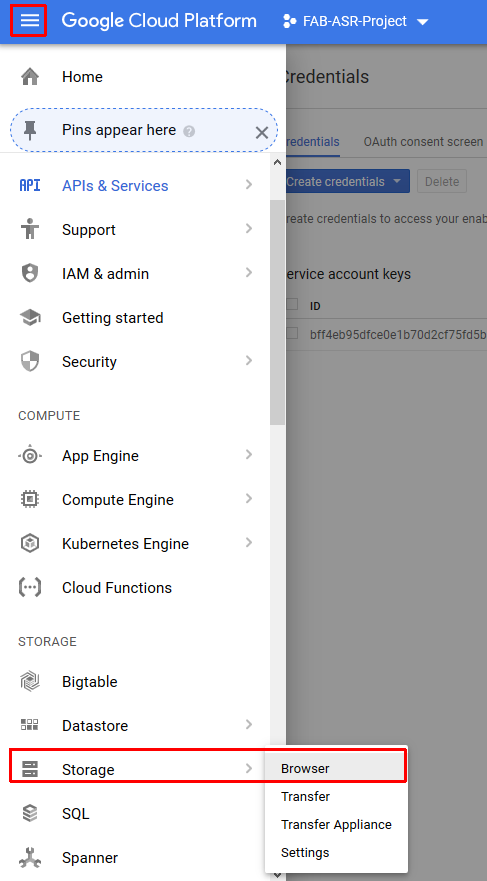
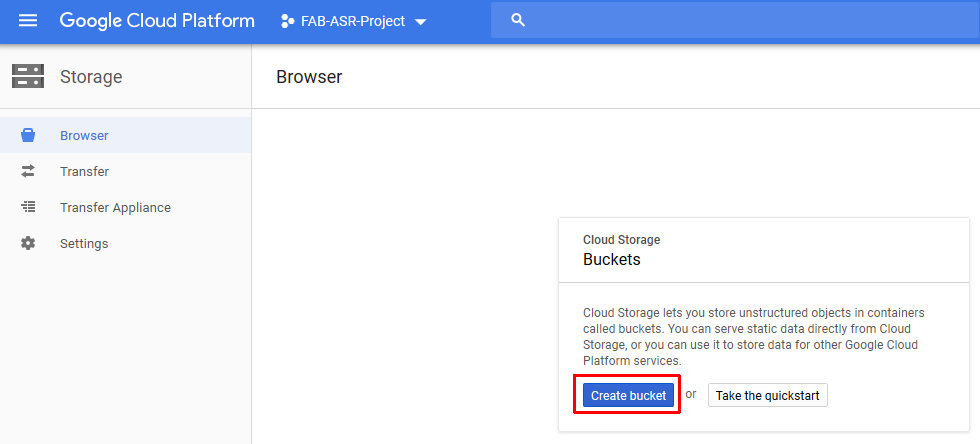
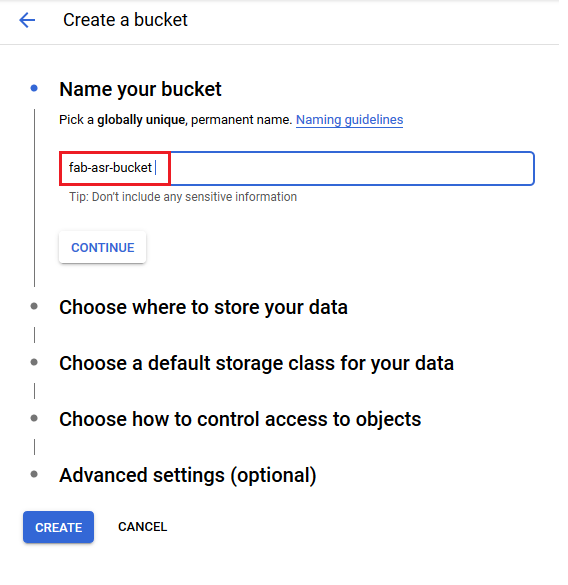
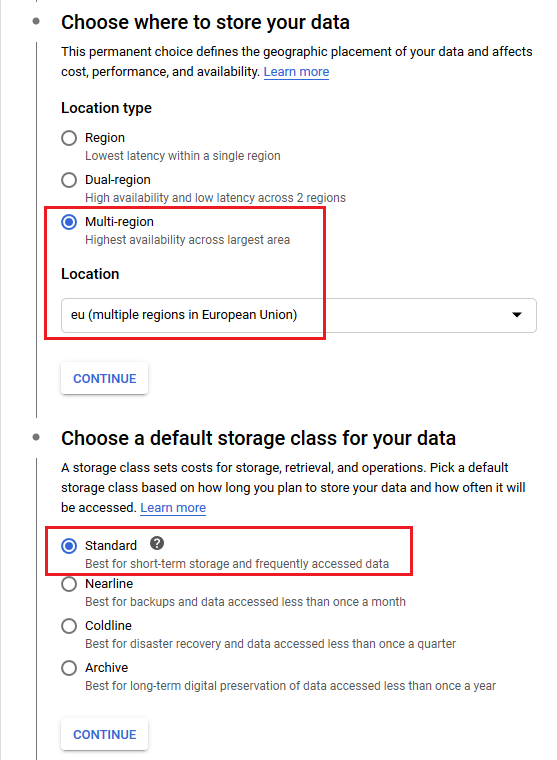
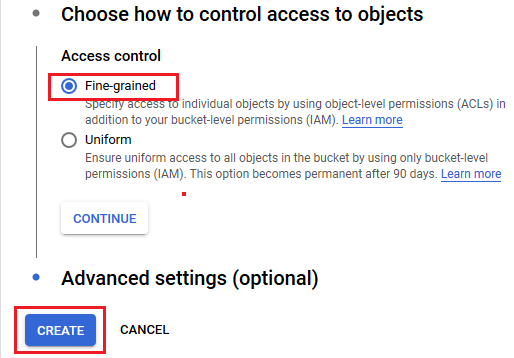
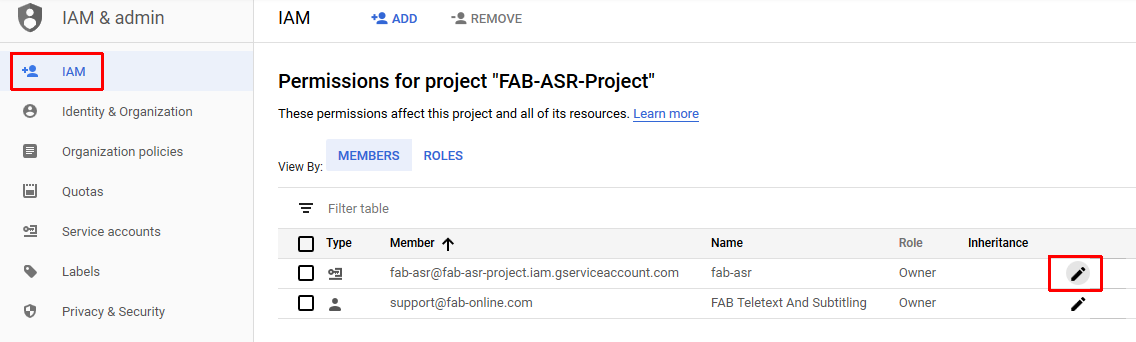
- Make sure to Add bucket permissions for the service account which you have created in one of the previous steps
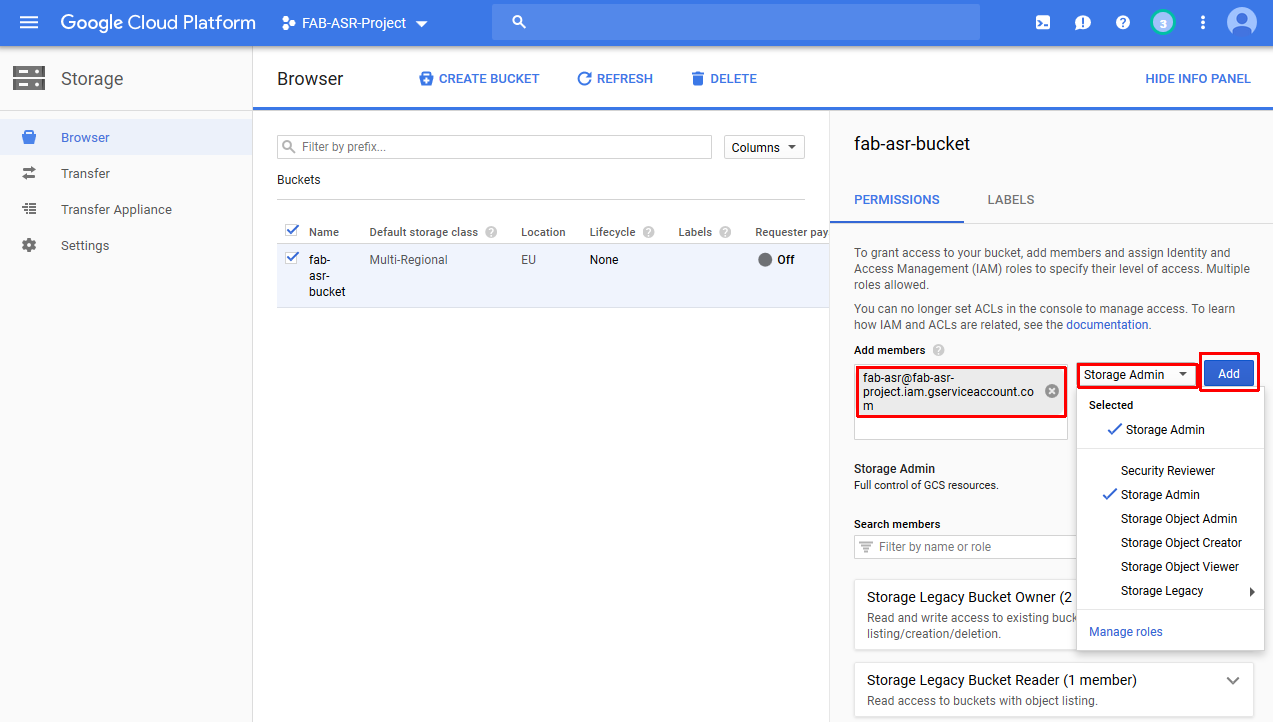
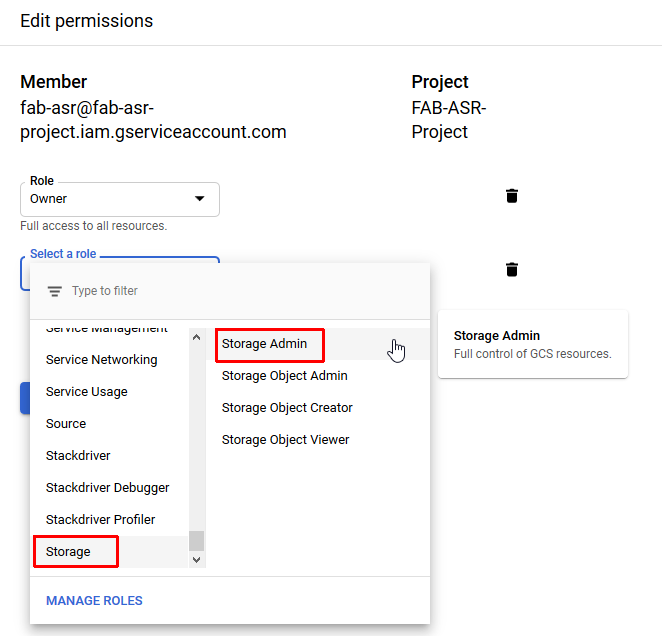
- Set “Storage Admin” role for the service account
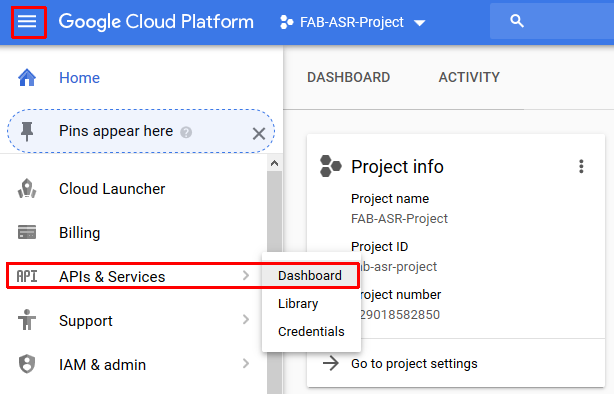
- Enable the cloud speech API
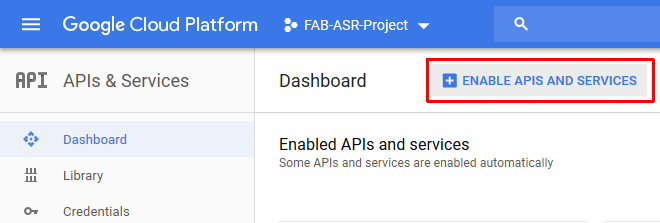
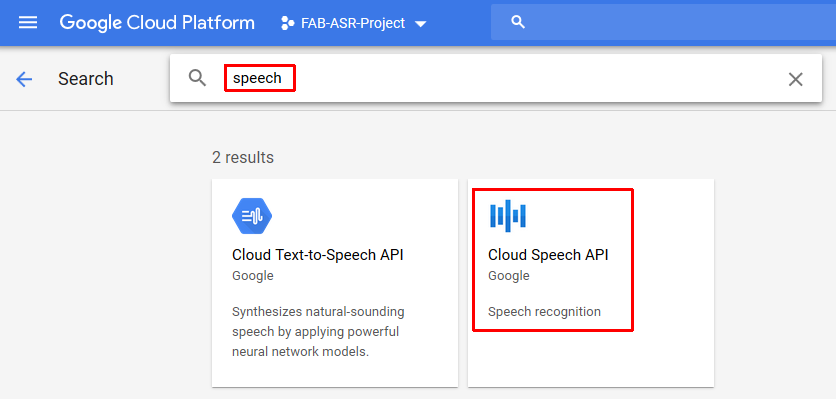
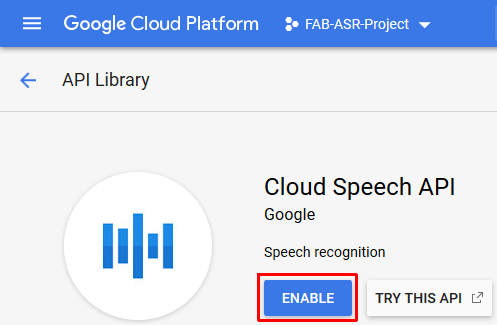
After configuring all above FAB Subtitler shall be able to use the transcription service of the Google cloud.
https://cloud.google.com/speech-to-text/
Using File Transcription Functionality in FAB Subtitler
To transfer video/audio files to the cloud transcription service click in the ribbon on Video / Transcribe File. A window will open which will display the status of the video analysis and allow uploading files to the cloud transcription service.
![]()
The upper part of the window allows selecting the video/audio file on the disk and the transfer of the file to the cloud transcription service is started when clicking on the button Start transfer. After the file analysis is finished, FAB Subtitler will download the JSON result file from the cloud transcription service and store it locally. After that FAB Subtitler will delete the video file in the cloud transcription service.
The lower part of the window displays the status of the file which has been transferred to the cloud transcription service:
- Uploading: the file is currently being transferred to the cloud transcription service
- Transcribing: the file is currently being transcribed by the cloud transcription service
- Completed: the file transcription is finished, FAB Subtitler will download the JSON result file when it becomes available in the cloud transcription service
- Failed: the transcription of the file has failed, the reason returned by the cloud transcription service will also be displayed
- Transcribed, available locally: JSON result files returned by the cloud transcription service which are stored in the local file folder and can be opened in FAB Subtitler as a subtitle file
- Other: any other status of the file provided by the cloud transcription service
Using JSON result files in FAB Subtitler
JSON files returned by cloud transcription services do not contain subtitles. JSON files contain the transcript. In most cases the JSON file contains a list of words with the time for every word. FAB Subtitler uses a very intelligent algorithm to open JSON files and create subtitles.
Simply open the JSON file in FAB Subtitler and subtitles will be created automatically. You will then be able to store subtitles in one of the available subtitle file formats supported by FAB Subtitler.
Using File Transcription in Automatic Watchfolder Mode
FAB Subtitler PRO/LIVE/MPEG can be configured to monitor folders and use transcription functionality (upload video files and download transcribed files) as soon as a video file is present in the watchfolder.
To configure this type of automatic operation:
- In Options/Special/Automation configure the following:
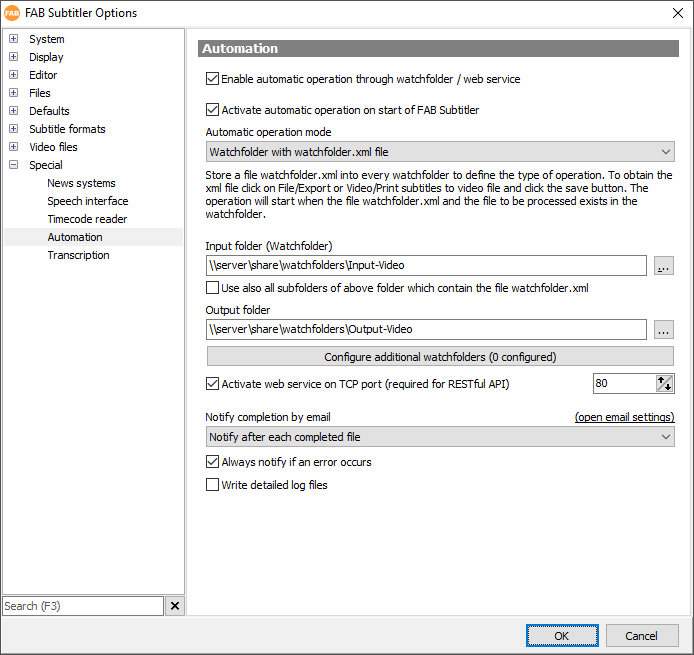
- Save a file with the name “watchfolder.xml” which contains conversion settings to the input folder by using the following procedure:
-
Click on Video / Transcribe
-
Select the transcription provider and choose all necessary settings
-
Click on the Save button which will save the XML file with all settings which are currently configured
![]()
-
Save the file with the name “watchfolder.xml” to the input folder
-
The automatic conversion operation will start when the file “watchfolder.xml” and the file to be processed both exist in the input folder
- To activate the automatic operation click on Extras / Tools > Start automatic mode
- To run FAB Subtitler in automatic mode in a 24/7 operation it is recommended to start FAB Subtitler using FAB Activity Manager. FAB Activity Manager will:
- Start FAB Subtitler
- Continuously check if FAB Subtitler is running correctly
- Restart FAB Subtitler if any problems are detected
Structure of JSON result files
Every transcription service uses a different JSON structure in the result file. To provide a JSON file with transcribed text to FAB Subtitler you can use the following simple JSON structure which is also used by the Google transcription.
- Note that “speakerTag” is used to define the color of the transcribed text. The value 0 corresponds to the first color defined in FAB subtitler.
- To instruct FAB Subtitler to not separate two words you can use the “Non breaking space” with the unicode code U+00A0
{
"name": "Name of content",
"metadata": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeMetadata",
"progressPercent": 100,
"startTime": "2017-10-22T19:16:28.581316Z",
"lastUpdateTime": "2017-10-22T19:27:59.757986Z"
},
"done": true,
"response": {
"@type": "type.googleapis.com/google.cloud.speech.v1.LongRunningRecognizeResponse",
"results": [
{
"alternatives": [
{
"transcript": "Sardinien hat viele Gesichter. Wilde Wälder",
"confidence": 0.8825865,
"speakerTag": "1",
"words": [
{
"startTime": "2s",
"endTime": "3.100s",
"word": "Sardinien"
},
{
"startTime": "3.100s",
"endTime": "3.300s",
"word": "hat"
},
{
"startTime": "3.300s",
"endTime": "3.600s",
"word": "viele"
},
{
"startTime": "3.600s",
"endTime": "3.800s",
"word": "Gesichter."
},
{
"startTime": "3.400s",
"endTime": "5.600s",
"word": "wilde",
"speakerTag": "2"
},
{
"startTime": "5.600s",
"endTime": "5.900s",
"word": "Wälder",
"speakerTag": "2"
}
]
}
]
},
{
"alternatives": [
{
"transcript": " und schroffe Berge es ist eine Insel auf der bunte Blüten explodieren und vernichtende feuerwalzen Blüten mit einer dunklen Unterwelt fantastischer Dortmund einer Vielzahl geflügelter Wesen Zuluft und auch zu Wasser typische Sachen besitzen besonderen Charme und Charakter",
"confidence": 0.9318773,
"speakerTag": "2",
"words": [
{
"startTime": "8.300s",
"endTime": "9.400s",
"word": "und"
},
{
"startTime": "9.400s",
"endTime": "9.800s",
"word": "schroffe"
},
{
"startTime": "9.800s",
"endTime": "10.200s",
"word": "Berge"
},
{
"startTime": "10.200s",
"endTime": "11.500s",
"word": "es",
"speakerTag": "3"
},
{
"startTime": "11.500s",
"endTime": "11.700s",
"word": "ist",
"speakerTag": "3"
},
{
"startTime": "11.700s",
"endTime": "12s",
"word": "eine",
"speakerTag": "3"
},
{
"startTime": "12s",
"endTime": "12.200s",
"word": "Insel",
"speakerTag": "3"
},
{
"startTime": "12.200s",
"endTime": "12.500s",
"word": "auf",
"speakerTag": "3"
},
{
"startTime": "12.500s",
"endTime": "12.700s",
"word": "der",
"speakerTag": "3"
},
{
"startTime": "12.700s",
"endTime": "13.100s",
"word": "bunte",
"speakerTag": "3"
},
{
"startTime": "13.100s",
"endTime": "13.600s",
"word": "Blüten",
"speakerTag": "3"
},
{
"startTime": "13.600s",
"endTime": "14.400s",
"word": "explodieren",
"speakerTag": "3"
},
{
"startTime": "14.400s",
"endTime": "14.600s",
"word": "und",
"speakerTag": "3"
},
{
"startTime": "14.600s",
"endTime": "18.100s",
"word": "vernichtende",
"speakerTag": "3"
},
{
"startTime": "18.100s",
"endTime": "18.900s",
"word": "feuerwalzen",
"speakerTag": "3"
},
{
"startTime": "18.900s",
"endTime": "19.300s",
"word": "Blüten",
"speakerTag": "3"
},
{
"startTime": "19.300s",
"endTime": "22s",
"word": "mit"
},
{
"startTime": "22s",
"endTime": "22s",
"word": "einer"
},
{
"startTime": "22s",
"endTime": "22.600s",
"word": "dunklen"
},
{
"startTime": "22.600s",
"endTime": "23.400s",
"word": "Unterwelt"
},
{
"startTime": "23.400s",
"endTime": "24.200s",
"word": "fantastischer"
},
{
"startTime": "24.200s",
"endTime": "24.800s",
"word": "Dortmund"
},
{
"startTime": "24.800s",
"endTime": "25.800s",
"word": "einer"
},
{
"startTime": "25.800s",
"endTime": "26.100s",
"word": "Vielzahl"
},
{
"startTime": "26.100s",
"endTime": "27.300s",
"word": "geflügelter"
},
{
"startTime": "27.300s",
"endTime": "27.700s",
"word": "Wesen"
},
{
"startTime": "27.700s",
"endTime": "29.600s",
"word": "Zuluft"
},
{
"startTime": "29.600s",
"endTime": "29.700s",
"word": "und"
},
{
"startTime": "29.700s",
"endTime": "32.500s",
"word": "auch"
},
{
"startTime": "32.500s",
"endTime": "32.800s",
"word": "zu"
},
{
"startTime": "32.800s",
"endTime": "33.200s",
"word": "Wasser"
},
{
"startTime": "33.200s",
"endTime": "37.600s",
"word": "typische"
},
{
"startTime": "37.600s",
"endTime": "37.900s",
"word": "Sachen"
},
{
"startTime": "37.900s",
"endTime": "38.300s",
"word": "besitzen"
},
{
"startTime": "38.300s",
"endTime": "39.100s",
"word": "besonderen"
},
{
"startTime": "39.100s",
"endTime": "39.300s",
"word": "Charme"
},
{
"startTime": "39.300s",
"endTime": "40.200s",
"word": "und"
},
{
"startTime": "40.200s",
"endTime": "40.500s",
"word": "Charakter"
}
]
}
]
}
]
}
}
This page was last updated on 2024-02-11